
This blog depicts the scenario for creating 2 AWS EMR clusters, where each cluster is assigned with 2 jobs to run simultaneously in it. So, 2 clusters with 4 jobs are orchestrated using Step Function. The plan is to create a flow that will have 2 Clusters which starts at the same time running 4 jobs in parallel – meaning, each cluster will run 2 jobs.
To execute this flow we have a feature introduced by AWS where 2 or more jobs can be executed in a single cluster simultaneously using StepConcurrencyLevel in EMR. This is used to reduce the runtime of the cluster, that can be performed using EMR console, AWS CLI or through AWS lambda.
The whole flow is orchestrated using Step Function, where the above mentioned logics can performed using the State Machine Language. This is instead of orchestrating another service like Lambda in Step Function to perform Step Concurrency. Hence, by using State Machine Language from Step Function one can perform concurrent EMR Job execution logic without another service support.
Execution Process
While creating the cluster using the State Machine Language, specify the StepConcurrencyLevel like 2 (or) 3, where the default is 1. Once it’s been specified, the no.of steps under that cluster are created and State Machine is run.
Now, the cluster will recognize the number of concurrency that has been set and will run the Steps accordingly.
NOTE: Only from emr-5.28.0 stepconcurrencylevel, argument is supported.
Below is the Flow Diagram based on the above State Machine Language Script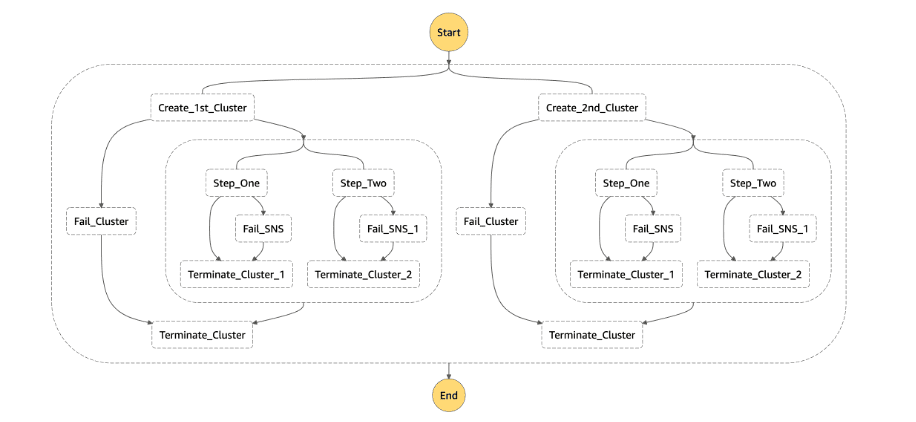
Sample Process on orchestrating a concurrent EMR execution using State Machine Language in Step Function
{
"StartAt": "ParallelEMRExecution",
"States": {
"ParallelEMRExecution": {
"Type": "Parallel",
"ResultPath": "$.step_fail",
"End": true,
"Branches": [
{
"StartAt": "Create_1st_Cluster",
"States": {
"Create_1st_Cluster": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:createCluster.sync",
"Parameters": {
"Name": "WorkflowCluster",
"StepConcurrencyLevel": 2,
"Tags": [
{
"Key": "Description",
"Value": "process"
},
{
"Key": "Name",
"Value": "filename"
},
{
"Key": "Owner",
"Value": "owner"
},
{
"Key": "Project",
"Value": "project"
},
{
"Key": "User",
"Value": "user"
}
],
"VisibleToAllUsers": true,
"ReleaseLabel": "emr-5.28.1",
"Applications": [
{
"Name": "Spark"
}
],
"ServiceRole": "EMR_DefaultRole",
"JobFlowRole": "EMR_EC2_DefaultRole",
"LogUri": "s3://prefix/prefix/log.txt/",
"Instances": {
"KeepJobFlowAliveWhenNoSteps": true,
"InstanceFleets": [
{
"InstanceFleetType": "MASTER",
"TargetSpotCapacity": 1,
"InstanceTypeConfigs": [
{
"InstanceType": "m4.xlarge",
"BidPriceAsPercentageOfOnDemandPrice": 90
}
]
},
{
"InstanceFleetType": "CORE",
"TargetSpotCapacity": 1,
"InstanceTypeConfigs": [
{
"InstanceType": "m4.xlarge",
"BidPriceAsPercentageOfOnDemandPrice": 90
}
]
}
]
}
},
"Retry": [
{
"ErrorEquals": [
"States.ALL"
],
"IntervalSeconds": 5,
"MaxAttempts": 1,
"BackoffRate": 2.5
}
],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "Fail_Cluster"
}
],
"ResultPath": "$.cluster",
"OutputPath": "$.cluster",
"Next": "Add_Steps_Parallel"
},
"Fail_Cluster": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "arn:aws:sns:us-west-2:919490798061:rsac_error_notification",
"Message.$": "$.Cause"
},
"Next": "Terminate_Cluster"
},
"Add_Steps_Parallel": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "Step_One",
"States": {
"Step_One": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:addStep.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"Step": {
"Name": "The first step",
"ActionOnFailure": "TERMINATE_CLUSTER",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"spark-submit",
"--deploy-mode",
"cluster",
"--master",
"yarn",
"--conf",
"spark.dynamicAllocation.enabled=true",
"--conf",
"maximizeResourceAllocation=true",
"--conf",
"spark.shuffle.service.enabled=true",
"--py-files",
"s3://prefix/prefix/pythonfile.py",
"s3://prefix/prefix/pythonfile.py"
]
}
}
},
"Retry": [
{
"ErrorEquals": [
"States.ALL"
],
"IntervalSeconds": 5,
"MaxAttempts": 1,
"BackoffRate": 2.5
}
],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.err_mgs",
"Next": "Fail_SNS"
}
],
"ResultPath": "$.step1",
"Next": "Terminate_Cluster_1"
},
"Fail_SNS": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "arn:aws:sns:us-west-2:919490798061:rsac_error_notification",
"Message.$": "$.err_mgs.Cause"
},
"ResultPath": "$.fail_cluster",
"Next": "Terminate_Cluster_1"
},
"Terminate_Cluster_1": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:terminateCluster.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId"
},
"End": true
}
}
},
{
"StartAt": "Step_Two",
"States": {
"Step_Two": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:addStep",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"Step": {
"Name": "The second step",
"ActionOnFailure": "TERMINATE_CLUSTER",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"spark-submit",
"--deploy-mode",
"cluster",
"--master",
"yarn",
"--conf",
"spark.dynamicAllocation.enabled=true",
"--conf",
"maximizeResourceAllocation=true",
"--conf",
"spark.shuffle.service.enabled=true",
"--py-files",
"s3://prefix/prefix/pythonfile.py",
"s3://prefix/prefix/pythonfile.py"
]
}
}
},
"Retry": [
{
"ErrorEquals": [
"States.ALL"
],
"IntervalSeconds": 5,
"MaxAttempts": 1,
"BackoffRate": 2.5
}
],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.err_mgs_1",
"Next": "Fail_SNS_1"
}
],
"ResultPath": "$.step2",
"Next": "Terminate_Cluster_2"
},
"Fail_SNS_1": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "arn:aws:sns:us-west-2:919490798061:rsac_error_notification",
"Message.$": "$.err_mgs_1.Cause"
},
"ResultPath": "$.fail_cluster_1",
"Next": "Terminate_Cluster_2"
},
"Terminate_Cluster_2": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:terminateCluster.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId"
},
"End": true
}
}
}
],
"ResultPath": "$.steps",
"Next": "Terminate_Cluster"
},
"Terminate_Cluster": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:terminateCluster.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId"
},
"End": true
}
}
},
{
"StartAt": "Create_2nd_Cluster",
"States": {
"Create_2nd_Cluster": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:createCluster.sync",
"Parameters": {
"Name": "WorkflowCluster",
"StepConcurrencyLevel": 2,
"Tags": [
{
"Key": "Description",
"Value": "process"
},
{
"Key": "Name",
"Value": "filename"
},
{
"Key": "Owner",
"Value": "owner"
},
{
"Key": "Project",
"Value": "roject"
},
{
"Key": "User",
"Value": "user"
}
],
"VisibleToAllUsers": true,
"ReleaseLabel": "emr-5.28.1",
"Applications": [
{
"Name": "Spark"
}
],
"ServiceRole": "EMR_DefaultRole",
"JobFlowRole": "EMR_EC2_DefaultRole",
"LogUri": "s3://prefix/prefix/log.txt/",
"Instances": {
"KeepJobFlowAliveWhenNoSteps": true,
"InstanceFleets": [
{
"InstanceFleetType": "MASTER",
"TargetSpotCapacity": 1,
"InstanceTypeConfigs": [
{
"InstanceType": "m4.xlarge",
"BidPriceAsPercentageOfOnDemandPrice": 90
}
]
},
{
"InstanceFleetType": "CORE",
"TargetSpotCapacity": 1,
"InstanceTypeConfigs": [
{
"InstanceType": "m4.xlarge",
"BidPriceAsPercentageOfOnDemandPrice": 90
}
]
}
]
}
},
"Retry": [
{
"ErrorEquals": [
"States.ALL"
],
"IntervalSeconds": 5,
"MaxAttempts": 1,
"BackoffRate": 2.5
}
],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "Fail_Cluster"
}
],
"ResultPath": "$.cluster",
"OutputPath": "$.cluster",
"Next": "Add_Steps_Parallel"
},
"Fail_Cluster": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "arn:aws:sns:us-west-2:919490798061:rsac_error_notification",
"Message.$": "$.Cause"
},
"Next": "Terminate_Cluster"
},
"Add_Steps_Parallel": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "Step_One",
"States": {
"Step_One": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:addStep.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"Step": {
"Name": "The first step",
"ActionOnFailure": "TERMINATE_CLUSTER",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"spark-submit",
"--deploy-mode",
"cluster",
"--master",
"yarn",
"--conf",
"spark.dynamicAllocation.enabled=true",
"--conf",
"maximizeResourceAllocation=true",
"--conf",
"spark.shuffle.service.enabled=true",
"--py-files",
"s3://prefix/prefix/pythonfile.py",
"s3://prefix/prefix/pythonfile.py"
]
}
}
},
"Retry": [
{
"ErrorEquals": [
"States.ALL"
],
"IntervalSeconds": 5,
"MaxAttempts": 1,
"BackoffRate": 2.5
}
],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.err_mgs",
"Next": "Fail_SNS"
}
],
"ResultPath": "$.step1",
"Next": "Terminate_Cluster_1"
},
"Fail_SNS": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "arn:aws:sns:us-west-2:919490798061:rsac_error_notification",
"Message.$": "$.err_mgs.Cause"
},
"ResultPath": "$.fail_cluster",
"Next": "Terminate_Cluster_1"
},
"Terminate_Cluster_1": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:terminateCluster.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId"
},
"End": true
}
}
},
{
"StartAt": "Step_Two",
"States": {
"Step_Two": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:addStep",
"Parameters": {
"ClusterId.$": "$.ClusterId",
"Step": {
"Name": "The second step",
"ActionOnFailure": "TERMINATE_CLUSTER",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"spark-submit",
"--deploy-mode",
"cluster",
"--master",
"yarn",
"--conf",
"spark.dynamicAllocation.enabled=true",
"--conf",
"maximizeResourceAllocation=true",
"--conf",
"spark.shuffle.service.enabled=true",
"--py-files",
"s3://prefix/prefix/pythonfile.py",
"s3://prefix/prefix/pythonfile.py"
]
}
}
},
"Retry": [
{
"ErrorEquals": [
"States.ALL"
],
"IntervalSeconds": 5,
"MaxAttempts": 1,
"BackoffRate": 2.5
}
],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.err_mgs_1",
"Next": "Fail_SNS_1"
}
],
"ResultPath": "$.step2",
"Next": "Terminate_Cluster_2"
},
"Fail_SNS_1": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "arn:aws:sns:us-west-2:919490798061:rsac_error_notification",
"Message.$": "$.err_mgs_1.Cause"
},
"ResultPath": "$.fail_cluster_1",
"Next": "Terminate_Cluster_2"
},
"Terminate_Cluster_2": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:terminateCluster.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId"
},
"End": true
}
}
}
],
"ResultPath": "$.steps",
"Next": "Terminate_Cluster"
},
"Terminate_Cluster": {
"Type": "Task",
"Resource": "arn:aws:states:::elasticmapreduce:terminateCluster.sync",
"Parameters": {
"ClusterId.$": "$.ClusterId"
},
"End": true
}
}
}
]
}
}
}
In this script (or) AWS Step Function’s State Machine Language, While creating the cluster, the StepConcurrencyLevel is mentioned as 2. Also 2 spark jobs is added as Steps below the cluster, meaning, this EMR cluster will run 2 jobs simultaneously.
When the above script is executed in Step Function, the cluster is orchested to run 2 steps concurrently, without directly configuring it in AWS EMR console (or) through AWS CLI and BOTO3.
Using State Machine Language orchestration of the flow, for a framework, can be done. A service can be customized (or) logic can be implemented as well, just the way the EMR cluster is customized to run 2 steps concurrently in a single cluster.
AWS Step Function is not just an orchestration tool but is much more. With State Machine Language, other services like lambda, livy API or BOTO3 can be avoided for less complex logic execution.
Performance Statistics after Parallel Execution
- On an average, it takes 8-10 mins to initialize and bootstrap a cluster. Now, by having a common cluster for multiple Jobs we can avoid such bottleneck situation and drastically reduce overall runtime, set of resources and EMR costs.
- Based on the amount of dataset used, the below table is drafted:
| DataSets | Total Source Data Size | EMR Runtime based on stacked execution | EMR Runtime based on parallel execution | EMR Cost based on stacked execution | EMR Cost based on parallel execution |
| Dataset A | 1 GB | 30 Minutes | 7 Minutes | $ 1 | $ 0.22 |
| Dataset B | 110 GB | 40 Minutes | 28 Minutes | $ 5 | $3.46 |
Pros and Cons of the method
Pros:
- Multiple EMR jobs can be run simultaneously to reduce Spark runtime.
- Simplify Amazon EMR resource configurations with fewer EMR clusters.
- The communication between StepFunction and EMR cluster won’t be affected.
- Since Parallel State is used in Step Function, even if cluster 1 fails, it will not impact cluster 2, such as stopping the whole process.
Cons:
- When a step concurrency level is selected for the cluster, one must consider whether or not the master node instance type meets the memory requirements of user workloads.
- The main step executer process runs on the master node for each step. Running multiple steps in parallel, requires more memory and CPU utilization from the master node than running one step at a time.
References
Reference link for State Machine Language: https://docs.aws.amazon.com/step-functions/latest/dg/connect-emr.html
