
Have you ever thought, “I wish I could just write code without all the extra fuss”? Well, you’re in the right place. Our journey is all about using Go to code without worrying about servers. It’s like having a self-driving car; just sit back and enjoy the ride.
This blog will outline the simplest method for establishing a serverless method using Go to retrieve user data and save it to DynamoDB, all while maintaining a light, friendly, and jargon-free approach.
While there are many excellent blogs for setting up Go Serverless, many do not focus on local development and do not enhance the development experience of writing Go lambdas. In this blog, tet’s delve deep into that.
The Serverless Framework
Let’s unwrap the concept of serverless with an analogy that’s both entertaining and enlightening. Imagine you’re planning a grand celebration (that’s your application). In the old days, you’d need to own a venue (a server) to host this bash. Sounds like a heap of responsibility, doesn’t it?
Enter the serverless world—it’s close to hiring an expert party planner. This planner takes care of everything—the venue, the setup, the clean-up. Similarly, you provide the code and leave the where and how of its execution to the experts.
Serverless computing lets you build and run applications without the burden of server management. It’s all about writing your code and letting a cloud provider run it. This provider handles the heavy lifting—scaling up or down as needed, maintaining the servers, and ensuring uptime. This provider acts as an invisible yet incredibly efficient helper, ensuring your app can effortlessly manage any number of guests or users.
This open-source wonder is not just a tool; it’s a wizard in your coding journey. Serverless Framework streamlines the process of deploying serverless applications, taking the tediousness out of server management. What sets the Serverless Framework apart from other tools? The Serverless Framework stands out due to its compatibility with various cloud providers. Though it began with a focus on AWS, it’s grown to support Azure, GCP, and many others. This support for multiple cloud providers ensures you don’t have to rely solely on one provider. You have the flexibility to choose or switch your cloud provider based on your needs.
Serverless Configuration
Equip Yourself with the Right Tools
Before we embark on this adventure, make sure you have two key items in your toolkit:
- Go – If Go isn’t already part of your developer toolkit, now is the time to welcome it aboard. Head over to the official Go website and grab the latest version. We’re focusing on Go 1.21 and above in this blog, so make sure you’re up-to-date. The installation is a simple process; just follow the instructions for your operating system, and you’re set!
- Serverless Framework – This nifty tool is like having a personal assistant for your serverless adventure. To get this assistant on board, simply run
npm install -g serverlessin your command line. This requires Node.js, so if you don’t have it yet, a quick trip to the node.js website will sort that out. As a bonus, we’ll sprinkle in somenodemonmagic to auto-reload our functions, making our development process smoother. - Boiler Plate Code – Let’s lay the foundation with some boilerplate code. Open your command line and run
serverless create --template aws-go --path go-serverless-api. Once done, step into your new project withcd go-serverless-api. Though it’s optional (since we’ll be customizing the Go file), it’s a fantastic starting point and sets the tone for our serverless application.
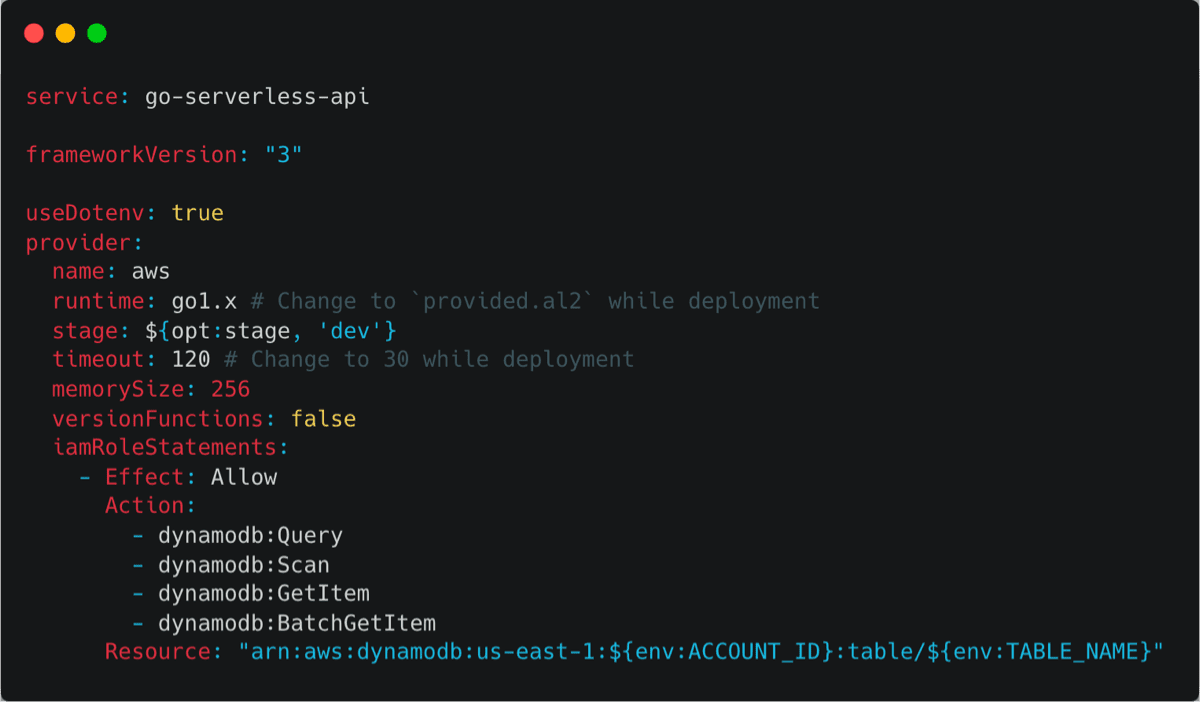
To ensure our serverless function can smoothly chat with DynamoDB, we need to grant the right permissions. Let’s add an IAM Role statement to our serverless.yml file that allows our function to access DynamoDB:
We will install three plugins to help the development process.
- serverless-offline, allows us to emulate AWS Lambda and API Gateway locally, thereby simplifying the testing process.
- serverless-dotenv-plugin,load your
.envfile variables automatically. It’s optional, though, if you prefer the manual approach. - On sls deploy, serverless-go-plugin, automatically compiles go functions. Say goodbye to manual build commands.
Install all of the plugins using your favorite package managers (mine is Bun), and we’ll add them to the serverless.yaml plugin section.

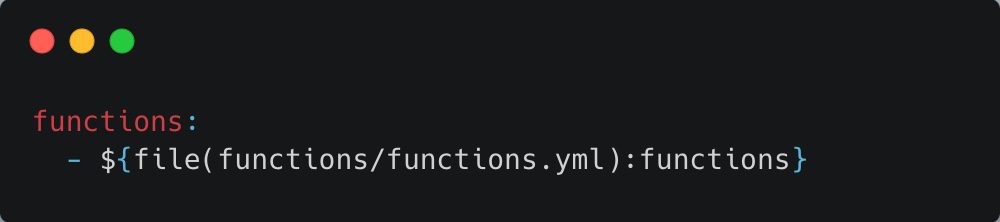
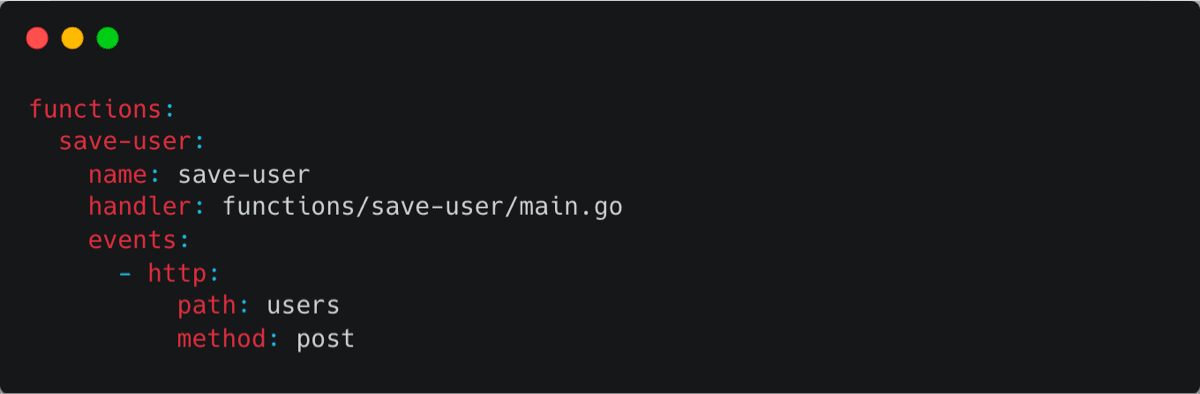
When it comes to adding functions to our serverless.yaml, it’s all about personal preference. However, as the number of functions grows, so does the complexity. To keep things neat and tidy, let’s define our functions in a separate .yaml file and mention them in our mainserverless.Yaml
We need a DynamoDB db to work with. You have two options: either use the local DynamoDB client (include the localhost url when creating the Dynamo client) or create a Dynamo table in AWS using default settings, naming the primary and sort keys pk andsk respectively.
Now that we have these tools, let’s embark on the next phase of our journey and begin creating some go-magic!
Serverless Function
Utilities
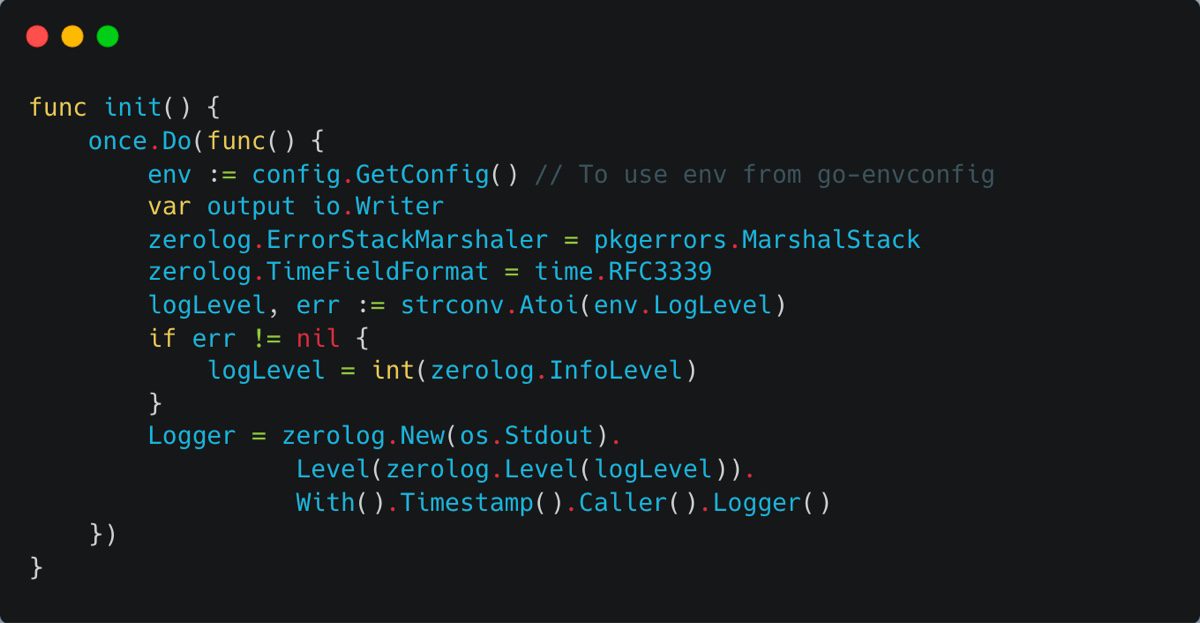
Logging with Zerolog
Effective logging is crucial for any function to gain insights and debug issues. We’re going to integrate zerolog, an excellent logging library known for its simplicity and performance. Here’s how we set it up as a utility:
Env management with go-envconfig
For managing environment variables, go-envconfig is our go-to solution. It simplifies loading and parsing environment configurations. You can find the setup code in the GitHub repository at the end.
Defining Structs
We’ll define auser struct with both JSON andDynamodbav tags. Dynamodbav tags specify column names in DynamoDB, while json tags parse data into this struct.
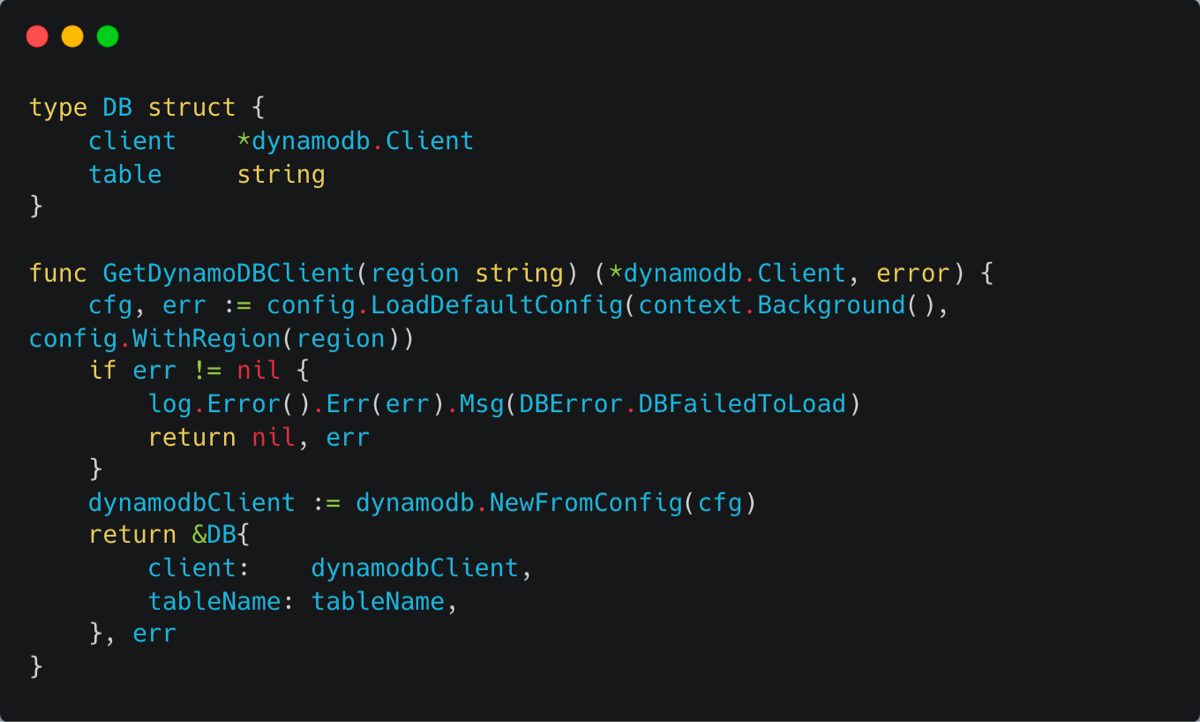
 Dynamo Wrappers
Dynamo Wrappers
Establishing a connection to DynamoDB is essential. Here’s a function to get a DynamoDB client:
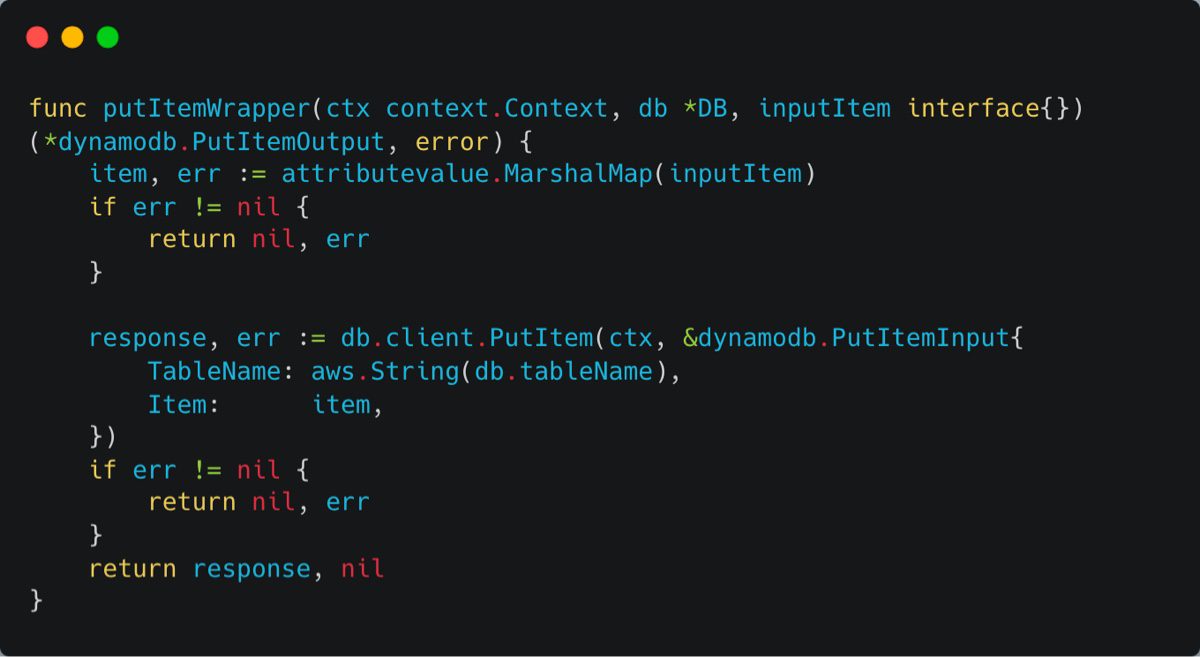
For storing data, we have a wrapper function that accepts any data type and saves it to DynamoDB:
Go Handler
Now, we reach the heart of our application—the Go handler function itself. This is where the magic happens, turning data into action. We’re using aws-lambda-go, the official AWS package for Go Lambda functions, to make this happen. Here’s a quick note on structure:
- The function should reside in the
mainpackage. - Only one handler file should exist at the same folder level. Only one handler file should exist at the same folder level. This is necessary to ensure the proper functioning of both the
serverless-offlineandserverless-go-plugin. - Feel free to organize utilities, types, and other components in separate files and import them into your handler.
Our handler parses the incoming request body and unmarshals it into our user struct before sending it to DynamoDB.

Note here that the JSONResponse utility makes it an effortless task for us to send back JSON responses, whether it’s an error, a struct response, or a map response.
For this project, I have considered the simplest access patterns.
- Save the user’s information.
- Retrieve the specified user ID.
You can expand access patterns using Global Secondary Indexes (GSIs). With support for up to 20 GSIs per table, DynamoDB offers plenty of flexibility for various query requirements.
We might need a function to return us a struct that has both the primary key and the user info. You can use this function for both put and get operations in DynamoDB.

And giving the output of this function to our previously written putItemWrapper would create the user for us in DynamoDB.

As a final step, remember to include our function definition within the function.yaml file, making sure to include our lambda for serverless deployments.
Conclusion
We can test our lambdas locally using the sls offline command, with nodemon for hot reloading. Make sure to check out the repo mentioned below.
With all the configuration in place, a simple sls deploy command in your terminal breathes life into your function. Hit Enter, and voilà—our serverless function is up and running, ready to save users to your DynamoDB table!
You can dive deeper into this Go serverless with more utilities and comprehensive implementations. Check out the complete codebase in this GitHub repo.
